Svaki veliki distribuirani sistem ima način da postigne konsenzus. To je digitalno rukovanje koje osigurava da se svaki čvor u klasteru slaže oko stanja sistema, čak i kada nastane haos. Više od decenije, tajno oružje Apache Kafke nije bilo njeno. Koristila je Apache ZooKeeper.
Ova kombinacija je bila ključna za rast Kafke, ali je imala svoju cenu. Upravljanje Kafka klasterom značilo je upravljanje sa dva složena distribuirana sistema. Ovo je bio izvor operativnih glavobolja.
Danas je ta era završena uvođenjem KRaft (Kafka Raft) protokola. Kafka se oslobodila. Upravlja sopstvenom sudbinom pomoću ugrađenog mehanizma za konsenzus. Ovo nije samo ažuriranje, već fundamentalno redizajniranje Kafke. Hajde da analiziramo zašto je ovaj potez tako velika pobeda.
Stari način: ZooKeeper
U prošlosti, Kafka klaster nije mogao da postoji bez ZooKeeper-a. ZooKeeper je bio centralni nervni sistem. Jedini izvor istine za sve metapodatke.
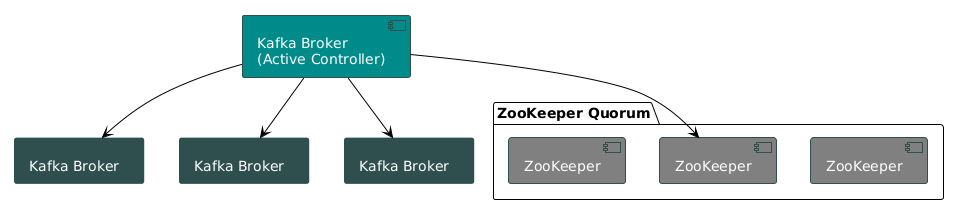
Evo kako je to funkcionisalo:
- Izbor kontrolera: ZooKeeper bi izabrao jednog Kafka brokera za kontrolera (određenog menadžera za ceo klaster).
- Jedini izvor istine: Svaka promena metapodataka (nova tema, otkazivanje brokera, ažuriranje konfiguracije) morala je prvo biti upisana u ZooKeeper.
- Igra gluvih telefona: Kontroler bi pratio promene u ZooKeeper-u i zatim bio odgovoran za njihovo prosleđivanje svim ostalim brokerima.
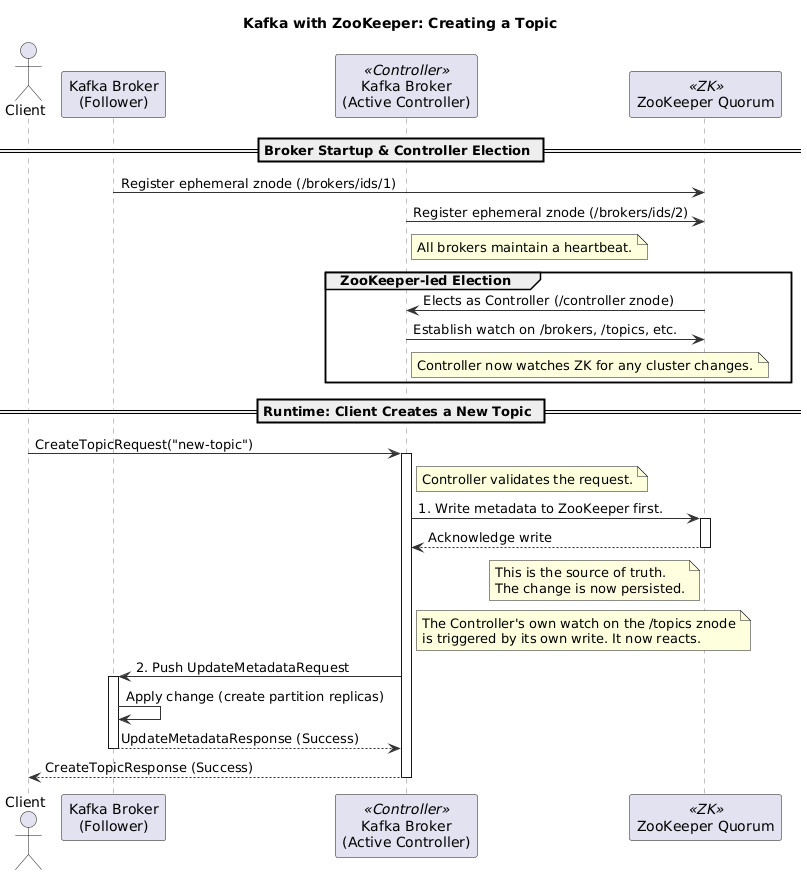
Operativna noćna mora
Za svakoga ko je koristio Kafku u velikom obimu, ova arhitektura je bila mač sa dve oštrice.
- Dva sistema (duplo više problema): Niste bili samo Kafka ekspert, morali ste biti i ZooKeeper ekspert. To je značilo odvojeno podešavanje, odvojeno praćenje, odvojenu bezbednost i čitav odvojen sistem za otklanjanje grešaka.
- ZooKeeper kao usko grlo: Kako su klasteri rasli, ZooKeeper je često postajao usko grlo. Sve administrativne komande su išle preko njega. To je ograničavalo brzinu kojom ste mogli da kreirate teme ili skalirate klaster.
- Spor oporavak od otkaza (failover): Ovo je bio pravi problem. Ako bi kontroler broker otkazao, proces oporavka je bio veoma spor. Izbor novog kontrolera i prisiljavanje da pročita celokupno stanje iz ZooKeeper-a moglo je da potraje desetine sekundi, pa čak i minute. U svetu visoke dostupnosti, to je čitava večnost nedostupnosti sistema.
Nova era: Kafka u KRaft režimu
Kafka zajednica je znala da mora postojati bolji način. Odgovor je bio KRaft, implementacija Raft algoritma za konsenzus koja se nalazi unutar same Kafke. Bez spoljnih zavisnosti, bez “split-brain” arhitekture.
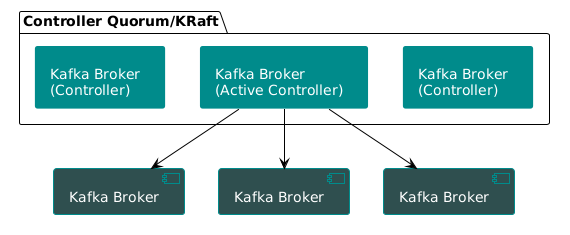
Novi način je jednostavan:
- Nekoliko brokera je određeno za kontrolere. Oni formiraju samostalni Raft kvorum.
- Svi metapodaci klastera se sada čuvaju u internoj Kafka topic-u:
__cluster_metadata. - Izabrani lider kvoruma kontrolera upisuje sve promene u ovaj log. Svaki drugi čvor u klasteru se jednostavno pretplaćuje na njega.
Elegancija je zapanjujuća: Kafka sada koristi sopstveni, u praksi dokazan, protokol za replikaciju da bi upravljala sopstvenim stanjem.
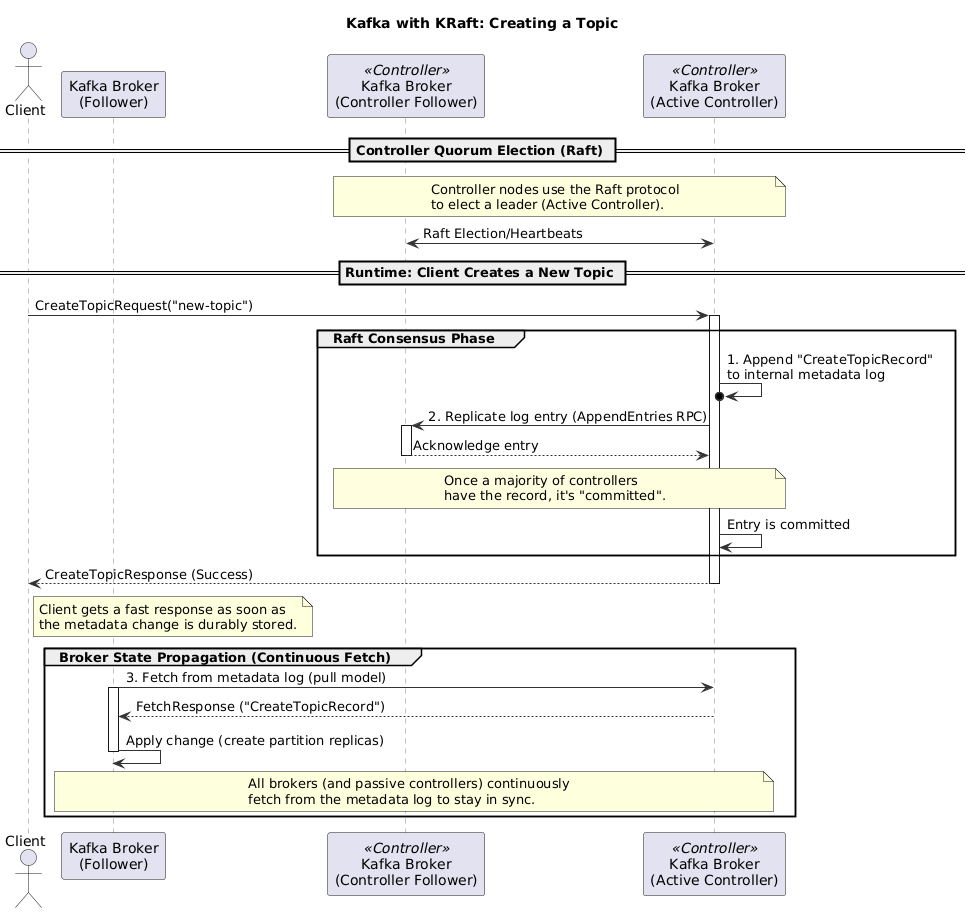
Obračun: Zašto KRaft pobeđuje bez premca
Ova arhitektonska promena donosi ogromne prednosti.
1. Radikalna jednostavnost
Najočiglednija pobeda? Možete da obrišete ZooKeeper okruženje. To znači manje infrastrukture za upravljanje, manje konfiguracija za usklađivanje i jedan, jedinstven sistem za nadgledanje i obezbeđivanje. Operativno opterećenje je prepolovljeno.
2. Brz oporavak
Ovo je apsolutna pobeda KRaft-a. Pošto je stanje klastera već replicirano između kontrolera u Kafka logu, oporavak od otkaza (failover) je skoro trenutan. Novi kontroler može preuzeti vođstvo za nekoliko sekundi, često i za manje od sekunde.
Grafikoni performansi govore sve:
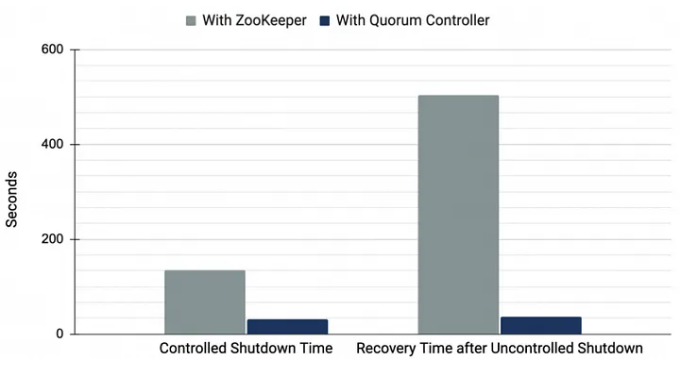
Pogledajte to vreme oporavka nakon nekontrolisanog gašenja. Razlika nije poboljšanje; to je potpuna transformacija. Ono što je nekada bio prekid rada dovoljan za pauzu za kafu, sada je gotovo za tren oka.
3. Skalabilnost
Bez ZooKeeper uskog grla, Kafka sada može podržati ogroman broj particija. Govorimo o skaliranju na milione particija u jednom klasteru, podvig koji je bio jednostavno nezamisliv u eri ZooKeeper-a, gde je gornja granica bila u stotinama hiljada.
Budućnost je bez ZooKeeper-a
Prelazak na KRaft nije samo nova funkcionalnost. To je temelj za sledeću deceniju Kafke. Čini Kafku jednostavnijom za rad, dramatično otpornijom i sposobnom za skaliranje do nivoa o kojima smo pre mogli samo da sanjamo.
Ako gradite novu platformu za podatke, izbor je očigledan. KRaft je spreman za produkciju i predstavlja jasan put napred. Vreme je da se oprostite od ZooKeeper-a i prigrlite bržu, jednostavniju i moćniju Kafku.