Every great distributed system has a way to achieve consensus. It’s the digital handshake that ensures every node in a cluster agrees on the state of the world, even when chaos strikes. For over a decade, Apache Kafka’s secret weapon wasn’t its own. It used Apache ZooKeeper.
This combination was essential for Kafka’s growth, but it came at a cost. Managing a Kafka cluster meant managing two complex distributed systems. This was a source of operational headaches.
Today, that era is over with the introduction of the KRaft (Kafka Raft) protocol. Kafka has broken free. It manages its own destiny with built-in consensus mechanism. This isn’t just an update, it’s a fundamental reimagining of Kafka’s core. Let’s break down why this move is such a massive win.
The Old Way: ZooKeeper
In the past, a Kafka cluster couldn’t exist without a ZooKeeper. ZooKeeper was the central nervous system. The single source of truth for all metadata.
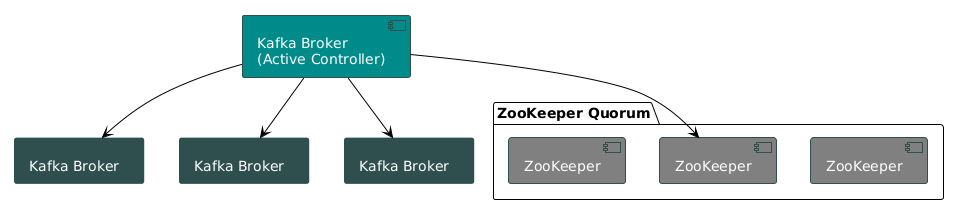
Here’s how it worked:
- The Controller Election: ZooKeeper would select one Kafka broker as the controller (the designated manager for the entire cluster).
- The Single Source of Truth: Every metadata change (a new topic, a broker failure, a configuration update) had to be written to ZooKeeper first.
- A Game of Telephone: The controller would watch ZooKeeper for these changes and then be responsible for propagating them to all the other brokers.
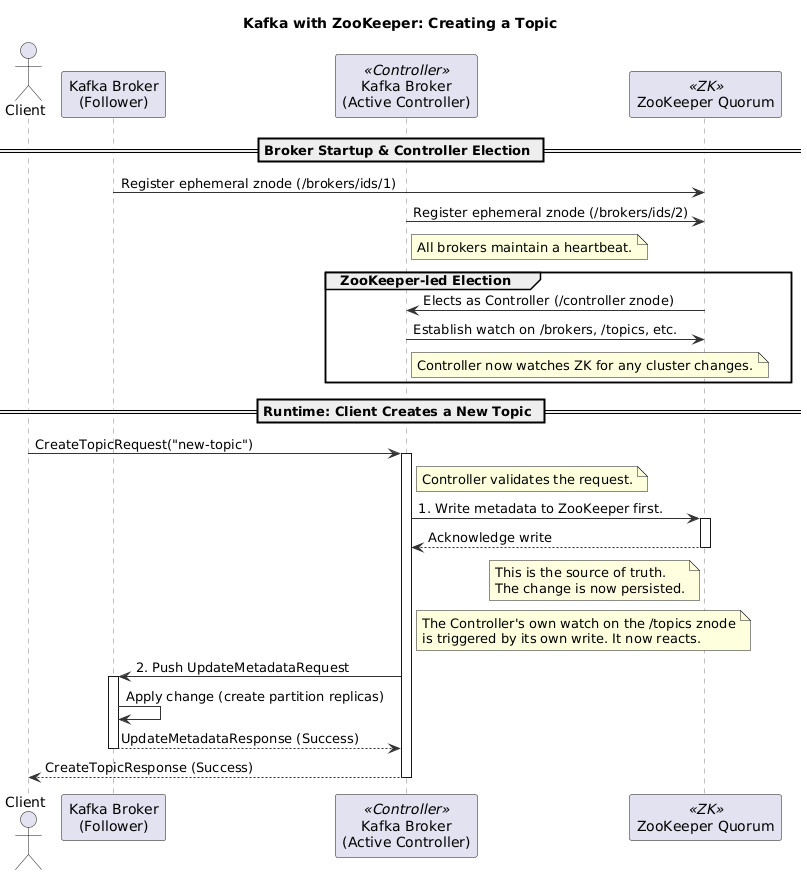
The Operational Nightmare
For anyone who ran Kafka at scale, this architecture was a double-edged sword.
- Two Systems (Twice the Trouble): You weren’t just a Kafka expert, you had to be a ZooKeeper expert. This meant separate provisioning, separate monitoring, separate security, and a whole separate system to debug.
- The ZooKeeper Bottleneck: As clusters grew, ZooKeeper often became a chokepoint. All administrative commands were directed through it. It limited how quickly you could create topics or scale your cluster.
- Slow Failovers: This was the real killer. If the controller broker failed, the recovery process was really slow. Electing a new controller and forcing it to read all the state from ZooKeeper could take dozens of seconds, or even minutes. In a high-availability world, that’s an eternity of downtime.
A New Dawn: Kafka in KRaft Mode
The Kafka community knew there had to be a better way. The answer was KRaft, an implementation of the Raft consensus algorithm that lives inside Kafka itself. No external dependencies, no split-brain architecture.
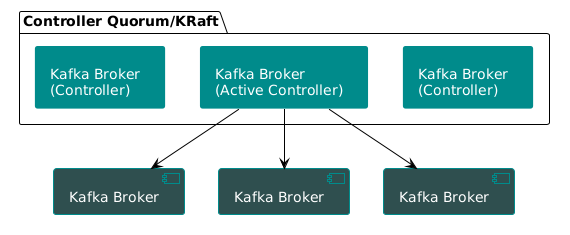
The new world is beautifully simple:
- A few brokers are designated as controllers. They form a self-contained Raft quorum.
- All cluster metadata is now stored in an internal Kafka topic:
__cluster_metadata. - The elected leader of the controller quorum writes all changes to this log. Every other node in the cluster simply subscribes to it.
The elegance is stunning: Kafka now uses its own battle-tested replication protocol to manage its own state.
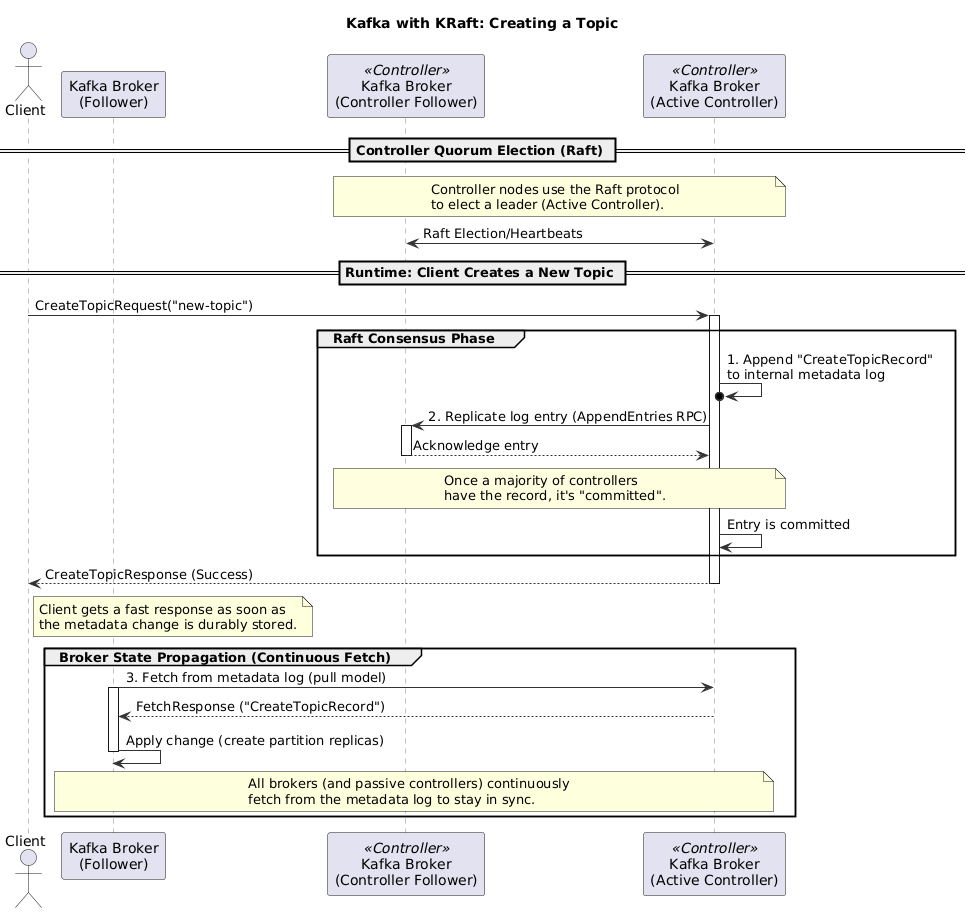
The Showdown: Why KRaft Wins, Hands Down
This architectural shift makes massive benefits.
1. Radical Simplicity
The most obvious win? You get to delete your ZooKeeper deployment. This means less infrastructure to manage, fewer configurations to juggle and a single, unified system to monitor and secure. The operational burden is cut in half.
2. From Minutes to Milliseconds: Lightning-Fast Recovery
This is KRaft’s absolute win. Because the cluster state is already replicated across the controllers in a Kafka log, failover is almost instantaneous. A new controller can take leadership in a few seconds, often sub-second.
The performance charts tell the whole story:
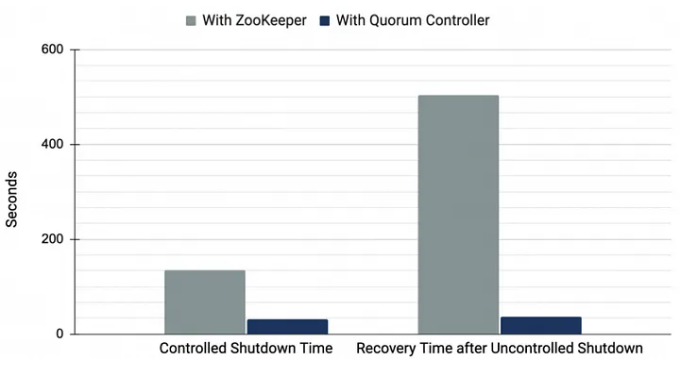
Look at that recovery time after an uncontrolled shutdown. The difference isn’t an improvement; it’s a complete transformation. What used to be a coffee break of downtime is now over in the blink of an eye.
3. Scaling
Without the ZooKeeper bottleneck, Kafka can now support a high number of partitions. We’re talking about scaling to millions of partitions in a single cluster, a feat that was simply unthinkable in the ZooKeeper era, which topped out in the hundreds of thousands.
The Future is ZooKeeper-less
The move to KRaft isn’t just a new feature. It’s the foundation for the next decade of Kafka. It makes Kafka simpler to operate, dramatically more resilient, and capable of scaling to levels we could only dream of before.
If you’re building a new data platform, the choice is a no-brainer. KRaft is production-ready and the clear path forward. It’s time to say goodbye to ZooKeeper and embrace a faster, simpler and more powerful Kafka.